

Nel 2004, l’informatico e blogger americano John Gruber inventò Markdown come ribellione contro la verbosità dell’HTML, un formato leggibile come testo piano destinato a blogger e sviluppatori. Oggi, nel 2026, esso struttura silenziosamente le risposte degli LLM come ChatGPT e Claude, dai grassetti agli elenchi, rivelando una “rivincita” inaspettata: da tool vintage a pilastro di archivi digitali a lungo termine, knowledge base personali e visioni minimaliste del web.
Un linguaggio contro la verbosità
Gruber, noto per il suo sito Daring Fireball (uno dei blog più letti al mondo), elaborò il Markdown insieme ad Aaron Swartz con un obiettivo preciso: scrivere per il web senza immergersi nei tag HTML né affidarsi agli editor visivi dell’epoca, che producevano codice gonfio e inconsistente. Il modello ispiratore era la posta elettronica in testo piano, leggibile direttamente senza bisogno di un programma di rendering, anche se esistevano altri linguaggi di marcatura nel mondo Unix e Linux come AsciiDoc, Org mode, reStructuredText. Il primo processore per Markdown fu scritto in Perl e la filosofia di fondo era netta: separare il contenuto dalla struttura, e la struttura dallo stile visivo.
Questa tripartizione non è banale. I linguaggi di marcatura come l’HTML separano già, almeno in teoria, la struttura semantica (cosa è un titolo, cosa è un paragrafo) dalla presentazione grafica (quale font, quale colore). Markdown radicalizza l’idea: la struttura emerge da convenzioni tipografiche immediate, come il cancelletto per i titoli o l’asterisco per il grassetto o il corsivo, e il testo rimane leggibile anche prima di qualsiasi rendering. È uno dei pochi formati (e sicuramente il più diffuso) in cui l’interprete può essere anche un essere umano che scrive e legge il sorgente grezzo, cosa praticamente impossibile con una pagina HTML.
La timeline del Markdown
| Anno | Evento | Significato |
|---|---|---|
| 2004 | John Gruber e Aaron Swartz pubblicano Markdown | Nasce un linguaggio di markup minimale pensato per scrivere HTML leggibile come testo |
| 2005–2008 | Diffusione tra blogger e sviluppatori | Markdown diventa popolare nei blog tecnici e nella documentazione software |
| 2009 | GitHub adotta Markdown | La piattaforma introduce il GitHub Flavored Markdown (GFM) e lo rende lo standard della documentazione open source |
| 2014 | Nasce il progetto CommonMark | Tentativo di definire una specifica rigorosa per eliminare le ambiguità della sintassi |
| 2016–2020 | Esplosione degli editor Markdown | Strumenti come Obsidian, iA Writer, Typora e Notion diffondono il formato tra scrittori e knowledge worker |
| 2020–2024 | Markdown domina la documentazione tecnica | Static site generator, wiki e knowledge base usano Markdown come formato principale |
| 2024–2026 | I modelli linguistici generano output in Markdown | LLM come ChatGPT e Claude usano Markdown per strutturare risposte leggibili e facilmente renderizzabili |
Un esempio di altri ambiti che seguono questo approccio è l’enciclopedia online più grande del mondo, Wikipedia, che conta decine di migliaia di collaboratori. Wikipedia utilizza principalmente un suo linguaggio di markup leggero chiamato Wikitesto (o Wikicode) per la formattazione dei contenuti, la creazione di collegamenti ipertestuali e la strutturazione delle pagine. Questo codice viene poi convertito in HTML dal software MediaWiki per la visualizzazione nei browser.
Markdown non è mai diventato uno standard formale e la sua evoluzione è stata guidata più dalla comunità che da specifiche ufficiali. Forse anche per questo si è diffuso rapidamente, evolvendo in varianti come il GitHub Flavored Markdown, che ha aggiunto tabelle e liste di controllo, diventando uno standard di fatto su Reddit, GitHub e decine di strumenti di documentazione.
Come funziona nella pratica
La sintassi di Markdown è intenzionalmente ridotta. I titoli si ottengono con uno o più cancelletti (#), il grassetto con doppi asterischi, il corsivo con uno solo o con il trattino basso, gli elenchi con trattini o numeri, i link con una notazione [testo](URL). I file hanno estensione .md o .txt e possono essere aperti e modificati con qualsiasi editor di testo, da BBEdit a VS Code passando per iA Writer. Strumenti come Pandoc li convertono in HTML, PDF o DOCX in pochi secondi.
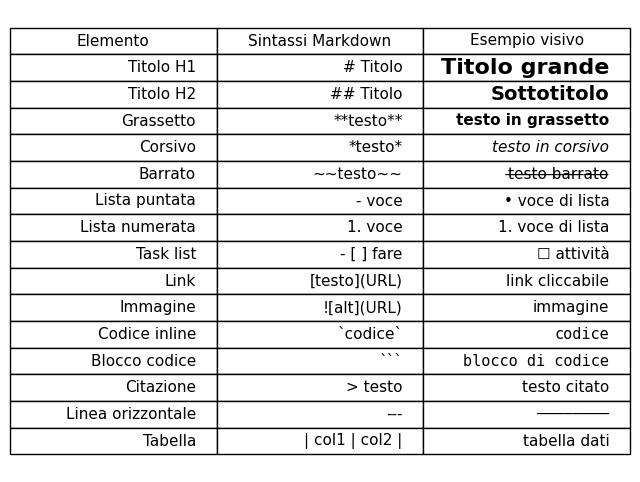
La forza pratica del formato sta nella sua natura duale: il sorgente è già leggibile da un essere umano, e il risultato renderizzato è formattato e navigabile. Un documento da mille parole con titoli, liste e tabelle occupa circa sette kilobyte, pochissimo rispetto ai quindici-trenta kilobyte di un file HTML equivalente o ai cinquanta-duecento kilobyte di un DOCX. La portabilità è totale: un file Markdown è testo codificato in UTF-8, versionabile con sistemi come Git, ricercabile con strumenti elementari, privo di dipendenze da software proprietari.
Questa leggerezza ha implicazioni archivistiche concrete. Il formato incarna la separazione tra contenuto (il testo), struttura (la gerarchia di titoli e liste) e stile (il CSS, il foglio di stile, che applica la veste grafica in fase di rendering): i file Markdown sono adatti a sopravvivere a decenni di obsolescenza tecnologica senza perdere né dati né leggibilità.
Il linguaggio nativo dell’AI
Il motivo per cui i grandi modelli linguistici si alimentano e generano output in Markdown non è casuale né decorativo. I modelli come GPT e Claude sono stati addestrati su enormi corpus di testo prelevato dal web, da GitHub, da repository di documentazione: ambienti dove Markdown è già il formato prevalente. La familiarità con il formato è quindi strutturale, non aggiunta a posteriori.
C’è poi una ragione economica molto concreta legata ai token, le unità in cui i modelli linguistici scompongono il testo per elaborarlo. Markdown è più conciso dell’HTML di circa il quaranta per cento in termini di token: la notazione **grassetto** pesa meno della sequenza <strong>grassetto</strong>. A parità di contenuto, un output in Markdown costa meno token da generare e da trasmettere. Con tariffe che oscillano tra i quindici e i sessanta dollari per milione di token a seconda del modello, la differenza si accumula rapidamente su larga scala. Il risparmio computazionale si traduce anche in consumi energetici inferiori e in risposte più veloci.
La struttura semantica che il Markdown impone, titoli gerarchici, elenchi, separazioni logiche, aiuta inoltre i modelli a organizzare le risposte in modo coerente, producendo output che risultano leggibili sia nelle interfacce che li renderizzano sia nelle integrazioni via API dove il testo arriva grezzo.
Il confronto tra standard
Secondo una serie di benchmark il Markdown presenta numerosi vantaggi rispetto ai formati come HTML e Docx.
| Parametro | Markdown (John Gruber, 2004; usi: docs dev, note, AI output) | HTML (Tim Berners-Lee, 1991; usi: web rendering, email) | DOCX (Microsoft, 2007; usi: office docs, report formali) |
|---|---|---|---|
| Dimensione file media (1k parole strutturate) | 5-10 KB (testo piano puro) | 15-30 KB (tag + entità) | 50-200 KB (XML zippato + binari immagini) |
| Velocità parsing/rendering (ops/sec su Node.js) | 5.000-5.700 ops/sec (Marked parser, 3x vs altri) | 2.000-2.300 ops/sec (browser nativo) | 100-500 ops/sec (Pandoc/LibreOffice) |
| Consumo GPU/CPU rendering (test 10 pagine) | Basso: <10% CPU, no GPU (testo-based) | Medio: 20-40% CPU/GPU (DOM parsing) | Alto: 50-80% CPU, GPU per preview (OOXML) |
| Token AI (LLM, es. GPT-4) | ~40% meno vs HTML (conciso: bold vs ) | Alto: tag verbosi (+60% token) | Molto alto: +200-300% (conversione testo prima) |
| Costo token AI ($/milione, input/output) | $15-30 (es. Grok/Claude, basso overhead) | $25-50 (+ token extra) | $50-100+ (pre-processing DOCX→testo) |
| Version control (Git diff) | Eccellente: diff leggibili, merge facili | Scarso: tag variabili, conflitti | Pessimo: binari, diff illeggibili |
| Portabilità archivio (10 anni) | Alta: testo eterno, grep/search nativo | Media: richiede parser HTML | Bassa: MS-dependent, corruzione zip |
| Conversione multi-formato (Pandoc) | Veloce: MD→HTML/PDF/DOCX in <1s | Media: HTML→altri ok, inverso lossy | Lenta: DOCX→altri con perdite layout |
| Risparmio storage (1GB corpus) | 1 GB puro → 0.8 GB compresso | 1.5-2 GB (tag ridondanti) | 3-5 GB (overhead binario) |
I vantaggi del Markdown
Markdown domina in performance per la sua natura minimalista: un documento da 1000 parole con titoli, liste e tabelle scritto in Markdown occupa circa 7 KB, parsabile a oltre 5000 operazioni al secondo, ideale per AI che generano output in real-time senza sovraccaricare risorse. HTML gonfia i file del doppio o triplo con tag semantici, richiedendo parsing DOM intensivo che aumenta i token del 60% negli LLM. DOCX è il meno efficiente: file 10-20 volte più grandi, parsing lento e alto consumo per la sua struttura OOXML zippata.
Nei contesti AI, il risparmio in token di Markdown si traduce in costi operativi inferiori del 40-60%: un output da 10.000 token in Markdown costa circa la metà rispetto a HTML. Per archivi a lungo termine, offre portabilità totale senza dipendenze proprietarie, con diff Git puliti per la collaborazione.
Il formato dei social e delle community
L’adozione del Markdown non si è fermata agli strumenti per sviluppatori. Reddit lo supporta nella sua variante GitHub Flavored Markdown per grassetti, corsivi, barrati, liste e blocchi di codice nei post e nei commenti. Discord usa un sottoinsieme simile per la formattazione nelle chat, con in più le barre verticali per i testi in spoiler. Mastodon, il social decentralizzato del fediverso, non ha ancora un supporto nativo standardizzato, ma ci sono proposte attive nella comunità degli sviluppatori per introdurre la formattazione di base, e intanto strumenti esterni convertono Markdown in post compatibili.
Applicativi di scrittura come ad esempio Obsidian hanno addirittura costruito un intero sistema di archiviazione e struttura dei contenuti privo di un database e centrato su semplici file di testo scritti in Markdown. Mentre i generatori di siti statici come Hugo e VuePress (o le stesse pagine di GitHub) permettono agli utenti di scrivere il contenuto in Markdown, applicare automaticamente uno stile (CSS) alla struttura e convertire il tutto in pagine web in frazioni di secondo. Questo, assieme alle librerie dei principali framework Javascript che permettono di rendere interattivi molti siti statici, ha reso competitivi molti siti statici rispetto alle piattaforme dinamiche come WordPress, che hanno requisiti tecnici e costi molto maggiori.
C’è anche un motivo meno tecnico e più letterario per cui Markdown ha conquistato tanti autori. Scrivere in Markdown significa tornare al testo puro, senza menu, pulsanti o barre di formattazione che interrompono il flusso del pensiero. I segni di formattazione sono pochi e familiari: un cancelletto per un titolo, un asterisco per l’enfasi, una riga vuota per respirare tra i paragrafi. Il risultato è un ambiente di scrittura minimalista quasi invisibile, dove la struttura del testo emerge mentre si scrive e non dopo. Per molti autori, dai blogger ai romanzieri che lavorano in editor minimalisti come iA Writer od Obsidian, Markdown diventa così una sorta di macchina da scrivere del web: semplice, stabile, concentrata sulle parole.
Il filo che unisce queste adozioni è sempre lo stesso: un formato leggero, espressivo, umano. La rivincita di Markdown, in fondo, è la rivincita di un’idea molto semplice: il testo appartiene prima di tutto a chi lo scrive e a chi lo legge, e sono le macchine, semmai, a doversi adattare.
Alcune fonti di questo articolo (inclusi i benchmark)
- https://daringfireball.net/projects/markdown/
- https://www.iana.org/assignments/markdown-variants/Original
- https://www.tomarkdown.org/guides/markdown-best-practice
- https://p.migdal.pl/blog/2025/02/markdown-saves/
- https://www.html.it/articoli/markdown-guida-al-linguaggio/
- https://www.jetbrains.com/help/writerside/markup-reference.html
- https://github.com/mpneuried/markdown-benchmark
- https://p.migdal.pl/blog/2025/02/markdown-saves/
- https://developers.google.com/style/markdown
- https://blog.fileformat.com/en/word-processing/markdown-or-docx-a-complete-guide-for-developers-and-technical-writers/
- https://stackoverflow.com/questions/32698263/pandoc-export-to-word-does-it-matter-whether-i-use-markdown-or-html-as-input-so
- https://unmarkdown.com/blog/why-every-ai-tool-writes-in-markdown
- https://www.reddit.com/r/AIMemory/comments/1r2pd8k/why_i_think_markdown_files_are_better_than/