

La corsa allo sviluppo del Large Language Model in grado di sbaragliare la concorrenza è in atto: ChatGPT, Claude, LLama, Gemini e decine di altri concorrenti si sfidano a botte di nuove versioni che vengono pubblicate a ritmi serratissimi, tanto da rendere il progresso in questo campo molto complesso da seguire.
In un precedente articolo abbiamo già parlato di questo fenomeno, che è naturalmente guidato da principi di marketing e competizione per il dominio di un settore che è divenuto di grande importanza.
Nello spirito di uno studio più cauto, con questo articolo ci addentriamo nei meandri di un tema molto importante: come si valuta un Large Language Model? In altre parole, cosa significa che “ChatGPT è meglio di Claude”?
Un esempio introduttivo
Prima di occuparci della valutazione dei LLMs, introduciamo un esempio semplificato per fare pratica con un po’ di nomenclatura e concetti importanti. Diciamo di disporre di due algoritmi diversi di sentiment analysis, chiamiamoli A1 e A2. Il task di sentiment analysis è piuttosto semplice: dato un Tweet, l’algoritmo deve identificarne il sentimento, che può essere positivo (1), neutro (2) o negativo (3).



Non ci interessa come funzionano questi algoritmi, ma immaginiamo nel nostro esempio che A1 e A2 siano sistemi basati su reti neurali e che il risultato della loro computazione sia un numero, che viene poi semplicemente convertito nei tre esiti positivo, negativo e neutro.
I benchmark
Siamo interessati a valutare le performance di A1 e A2 per determinare quale dei due sia il miglior algoritmo di sentiment analysis. Per fare ciò, dobbiamo ricorrere a un benchmark. Un benchmark è una sorta di test (come una verifica a scuola) al quale entrambi i sistemi vengono sottoposti.
L’approccio più classico è quello di utilizzare un benchmark pubblico già conosciuto, ma a fine illustrativo ipotizziamo di crearne uno noi. Selezioniamo una collezione di tweet e li annotiamo manualmente: uno o più umani, esperti del problema, leggono ognuno di questi 100 Tweet e annotano il loro sentimento. Ricorrendo alla metafora della verifica possiamo dire che il docente deve annotare la risposta alle domande della verifica per poter poi valutare i suoi studenti. Terminata la fase di annotazione, otteniamo qualcosa del genere:
| # Tweet | Testo Tweet | Annotazione del sentimento |
|---|---|---|
| 1 | La nuova riforma è ributtante, assurdo… | negativo |
| 2 | Giornata di sole con Marco, è stato splendido! | positivo |
| 3 | È uscito il nuovo Topolino, numero 2094 | neutro |
| … | ||
| 100 | Oggi sono stanchissima… odio il mio lavoro. | negativo |
Non resta che prendere questi 100 Tweet e sottoporli sia ad A1 che A2 (naturalmente, privati dell’annotazione degli umani).
Raccogliamo le risposte dei due sistemi e poi, confrontandole con le risposte annotate, procediamo a calcolare la loro accuratezza. Riportiamo i risultati in questo modo:
| System on benchmark X | Accuracy |
|---|---|
| A1 | 74% |
| A2 | 98% |
Significa che A1 ha trovato il sentimento corretto per 74 Tweet su 100, mentre A2 ne ha trovati 98 su 100. È chiaro: A2 è meglio di A1.
Il rischio di data contamination
C’è una condizione fondamentale affinché questa valutazione sia sensata: né A1 né A2 devono aver visto i dati del benchmark in fase di allenamento. Cosa significa? Dobbiamo ricordare che le reti neurali vengono prima allenate e poi usate. Non entriamo nel dettaglio, ma l’allenamento di una rete neurale consta sostanzialmente nel sottoporre al sistema migliaia (o milioni o miliardi) di esempi del problema per far sì che la rete impari a risolverlo.
Risulta dunque evidente che se gli esempi che abbiamo inserito nel benchmark sono stati visti dalla rete in fase di allenamento, i risultati della valutazione sono falsati! È come se uno studente avesse le risposte alla verifica il giorno prima… non stiamo valutando la sua capacità di risolvere le domande, ma tuttalpiù la sua capacità di ricordarsi qualcosa che ha già visto.
Questo fenomeno viene detto data contamination e nel contesto dei LLM assume una importanza cruciale, come capiremo fra poco.
Valutare un LLM
Rispetto all’esempio semplificato che abbiamo appena visto, valutare i LLMs introduce alcune complicazioni notevoli. Per loro natura i LLMs sono in grado di risolvere potenzialmente tanti task diversi. Infatti, a GPT possiamo chiedere di individuare il sentimento di un Tweet, ma anche di risolvere un indovinello così come di riassumere un testo. Perciò, anziché un benchmark solo si ricorre ad una batteria di benchmark ed ogni benchmark valuterà una specifica “abilità” del LLM in questione.
L’ulteriore complicazione sta nel fatto che per interrogare i LLM (e per leggere le risposte) si fa uso di una interfaccia linguistica: questo fa sì che un LLM possa essere interrogato ad esempio più volte, oppure con un prompt leggermente diverso e questo può avere grande impatto sulla risposta (e quindi sulla valutazione). In altre parole, usando il linguaggio naturale per interrogare e leggere le risposte di un LLM c’è molta più variabilità rispetto ad un classico sistema di machine learning.
È così che la semplice tabellina di valutazione di prima può diventare molto molto più complessa:
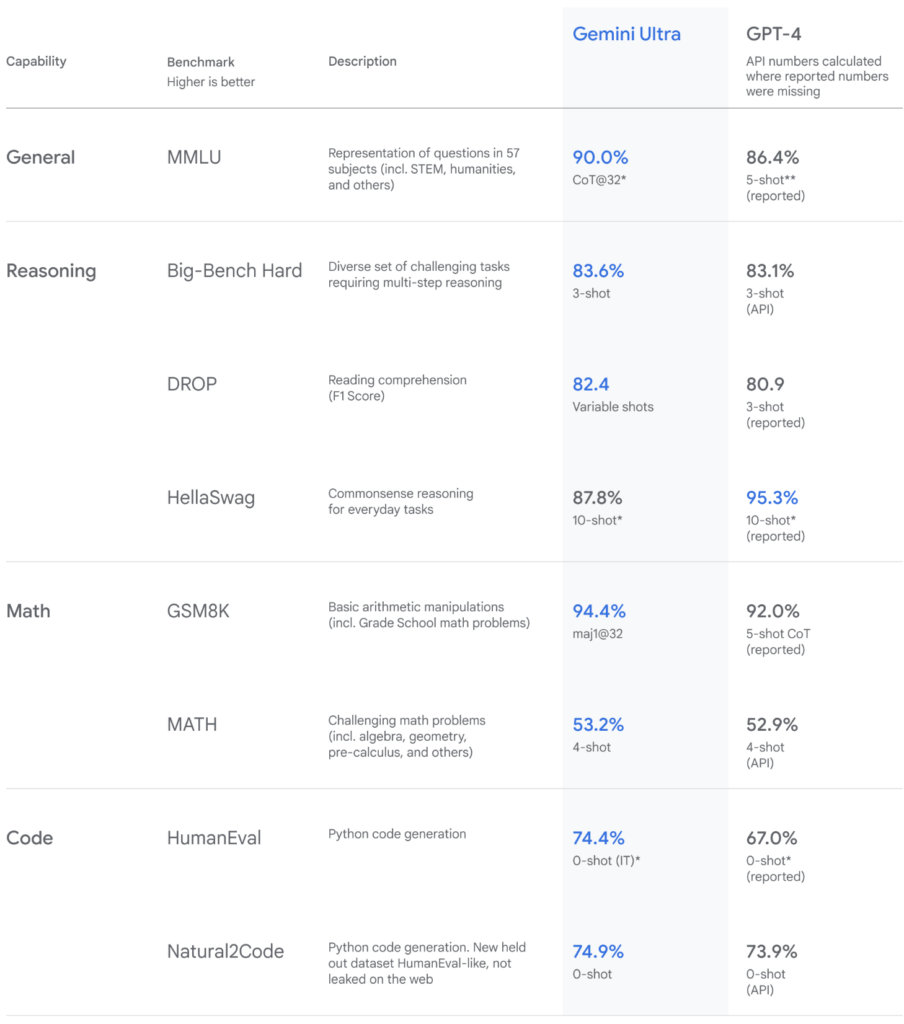
Qui osserviamo quattro task diversi: generale, ragionamento, calcolo matematico e codice. Ognuno ha diversi benchmark, ad esempio DROP è un benchmark che contiene una serie di domande di comprensione del testo. Ecco un esempio:

In questo caso si ha uno stralcio di testo e la domanda a cui il LLM deve rispondere è quanti goal hanno fatto i Lions? La risposta è 2.
Come anticipato, poi, ci sono complicazioni in merito alla modalità di interrogazione del modello, ossia la costruzione del/dei prompt. Osserviamo queste diciture:

CoT è un metodo diverso di interrogare LLM rispetto a n-shot e nel primo caso abbiamo specificamente CoT@32 mentre nel secondo abbiamo 5-shot. Non abbiamo tempo per addentrarci nelle differenze fra queste due metodologie, ma la domanda è: sono davvero comparabili? O stiamo confrontando le proverbiali carote con patate?
LLMs e data contamination
È pratica comune nel mondo scientifico specificare esattamente su quali dati viene fatto l’allenamento dei propri sistemi. Questo per ovvi motivi di riproducibilità scientifica. Ma, poiché i player nel mondo dei LLMs non sono entità solo scientifiche, ma sono soprattutto aziende, molte delle procedure che vengono usate per creare questi sistemi vengono nascoste. Certo, i vari scientific report danno qualche informazione (a volte anche parecchie), ma mai abbastanza per ricostruire esattamente quali dati sono stati forniti in allenamento ad una rete (neanche nei sistemi “open source” di Meta — che infatti sono tecnicamente open weights e non open source).
In questi due anni si è reso evidente che i due fattori sui quali si può agire per migliorare le performance dei sistemi sono a) Aumentare le dimensioni della rete b) Allenare le reti su dati di maggiore qualità. La scelta dei dati di allenamento costituisce quindi un importante segreto industriale. Ma questo è un problema! Perché non sapendo quali dati sono usati in input, la comunità scientifica non può contro-verificare la presenza di data contamination.
Sono infatti ormai moltissime [1, 2, 3] le testimonianze scientifiche che parlano del problema e tentano di stimare la quantità di data contamination nei più grandi LLM commerciali. Lo stesso technical report di Llama 3.1 [4] (Sezione 5.1.4) fornisce una analisi dettagliata del livello di contaminazione sui benchmark utilizzati… questa contaminazione è stimata avere un impatto sulle performance fino al 40% su alcuni benchmark!
Le alternative
Se è vero (e lo è) che i benchmark storici sono ormai compromessi e le valutazioni su di essi sono da ritenersi al più una vaga indicazione delle performance dei vari modelli, possiamo comunque ricorrere ad altri sistemi di valutazione.
Valutazione umana
Sempre nel report di Llama 3.1, abbiamo ad esempio una valutazione umana:
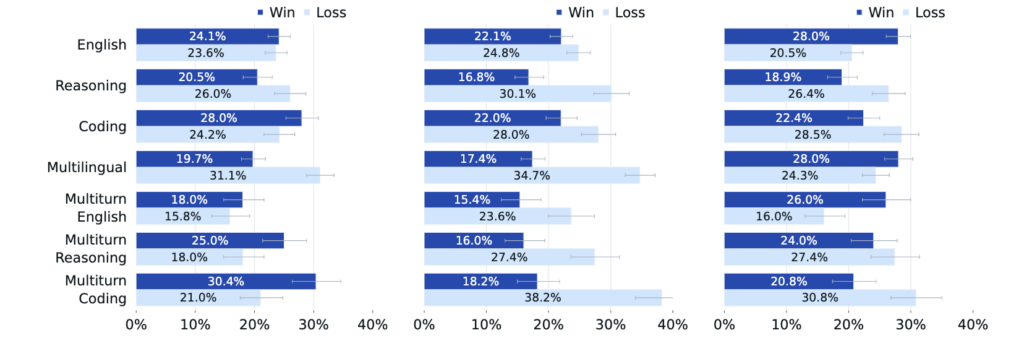
Qui la valutazione è svolta in modo diverso, comparativo: sono stati costruiti 7.000 prompt e sono stati sottoposti a Llama 3.1, GPT-4, GPT4o e Claude Sonnet. Poi, ogni prompt è stato valutato da umani i quali hanno dovuto scegliere la risposta migliore (il “vincitore”) confrontando i vari modelli a due a due (Llama vs ognuno degli altri) — I pareggi sono stati esclusi. Da questa valutazione possiamo ad esempio osservare come GPT4o, nel campo del reasoning, dia la risposta migliore nel 30% delle volte, mentre Llama nel 16% circa. Questo tipo di valutazioni sono importanti per capire ad esempio quale modello utilizzare a seconda del tipo di richiesta che dobbiamo soddisfare.
Chatbot Arena
Un tipo di valutazione simile è quella offerta dalla LMSYS Chatbot Arena, che in sostanza riproduce l’esperimento di cui sopra ma su vastissima scala: si tratta di più di 1 milione e mezzo di confronti effettuati da utenti. Ogni volta che un sistema vince guadagna punti (arena score), ogni volta che viene sconfitto ne perde.
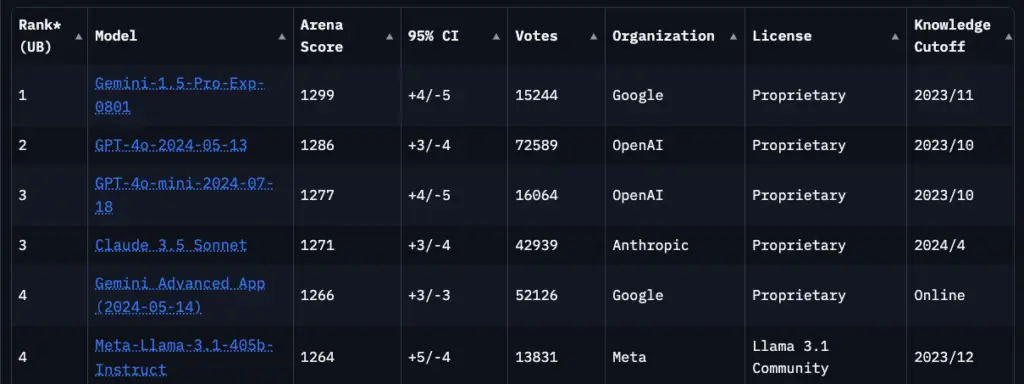
Il limite di questo approccio è che i prompt sono costruiti liberamente dagli utenti e quindi non costituiscono necessariamente una valutazione eterogenea e approfondita di tutte le capacità di un LLM. D’altro canto, si può interpretare come una valutazione delle “domande tipiche” e quindi dei reali casi d’uso di un LLM.
Infine, si sta valutando in letteratura [5] l’uso di benchmark privati, i quali però richiederebbero una serie di condizioni d’uso, implementazione e garanzie non banali.
Se si ha intenzione di impiegare LLMs in contesti aziendali (nei quali le performance sono importanti) l’unica soluzione è quella di affidarsi ad esperti e partire dalla costruzione di un benchmark interno: scegliere una batteria di possibili sistemi candidati e valutare quei sistemi sui propri benchmark interni. Attenzione però: costruire un benchmark sensato ed efficace non è semplice, quindi il suggerimento è di diffidare da vostro cugino che ve lo fa a 15 euro.
Una parola conclusiva
In questo articolo abbiamo toccato il tema della valutazione dei LLM e abbiamo mostrato come sia non banale stabilire quale sia il “miglior sistema”: le misurazioni relative alle performance di questi sistemi -specialmente quando fornite dai loro produttori- devono essere lette e interpretate con attenzione.
Naturalmente questo testo non costituisce una trattazione completa del problema, ma una infarinatura sufficiente a mostrarne le criticità. L’intento non è quello di essere disfattisti e minimizzare il progresso portato da questa straordinaria tecnologia, ma si vuole invitare alla cautela, fornendo un piccolo antidoto all’information overload al quale siamo sottoposti quando si parla di AI.
Fonti/Bibliografia
[1] Sainz, Oscar, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. “NLP Evaluation in Trouble: On the Need to Measure LLM Data Contamination for Each Benchmark.” In Findings of the Association for Computational Linguistics: EMNLP 2023, edited by Houda Bouamor, Juan Pino, and Kalika Bali, 10776–87. Stroudsburg, PA, USA: Association for Computational Linguistics.
[2] Aiyappa, Rachith, Jisun An, Haewoon Kwak, and Yong-Yeol Ahn. 2023. “Can We Trust the Evaluation on CHatGPT?” In Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), edited by Anaelia Ovalle, Kai-Wei Chang, Ninareh Mehrabi, Yada Pruksachatkun, Aram Galystan, Jwala Dhamala, Apurv Verma, Trista Cao, Anoop Kumar, and Rahul Gupta, 47–54. Toronto, Canada: Association for Computational Linguistics.
[3] Balloccu, Simone, Patrícia Schmidtová, Mateusz Lango, and Ondřej Dušek. 2024. “Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs.” arXiv [Cs.CL]. arXiv. http://arxiv.org/abs/2402.03927.
[4] Dubey, Abhimanyu, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. 2024. “The Llama 3 Herd of Models.” arXiv [Cs.AI]. arXiv. http://arxiv.org/abs/2407.21783.
[5] Rajore, Tanmay, Nishanth Chandran, Sunayana Sitaram, Divya Gupta, Rahul Sharma, Kashish Mittal, and Manohar Swaminathan. 2024. “TRUCE: Private Benchmarking to Prevent Contamination and Improve Comparative Evaluation of LLMs.” arXiv [Cs.CR]. arXiv. http://arxiv.org/abs/2403.00393.